[SQL] SQL 기본 및 활용 3
최적화 기본 원리
옵티마이저
옵티마이저(Optimizer)는 사용자가 질의한 SQL문에 대해 최적의 실행 방법을 결정하는 역할을 수행한다. 이러한 최적의 실행 방법을 실행계획(Execution Plan)이라고 한다.
규칙기반 옵티마이저(RBO, Rule Based Optimizer)
규칙기반 옵티마이저는 규칙(우선 순위)을 가지고 실행계획을 생성한다.
규칙기반 옵티마이저의 규칙
| 순위 | 액세스 기법 |
|---|---|
| 1 | Single row by rowid |
| 2 | Single row by cluster join |
| 3 | Single row by hash cluster key with unique or primary key |
| 4 | Single row by unique or primary key |
| 5 | Cluster join |
| 6 | Hash cluster key |
| 7 | Indexed cluster key |
| 8 | Composite index |
| 9 | Single column index |
| 10 | Bounded range search on indexed columns |
| 11 | Unbounded range search on indexed columns |
| 12 | Sort merge join |
| 13 | MAX or MIN of indexed column |
| 14 | ORDER BY on indexed column |
| 15 | Full table scan |
순위의 숫자가 낮을수록 높은 우선 순위이다.
- 규칙 1. Single row by rowid : ROWID를 통해서 테이블에서 하나의 행을 액세스하는 방식이다. ROWID는 행이 포함된 데이터 파일, 블록 등의 정보를 가지고 있기 때문에 다른 정보를 참조하지 않고도 바로 원하는 행을 액세스할 수 있다. 하나의 행을 액세스하는 가장 빠른 방법이다.
- 규칙 4. Single row by unique or primary key : 유일한 인덱스(Unique Index)를 통해서 하나의 행을 액세스하는 방식이다. 이 방식은 인덱스를 먼저 액세스하고 인덱스를 존재하는 ROWID를 추출하여 테이블의 행을 액세스한다.
비용기반 옵티마이저(CBO, Cost Based Optimize)
테이블 및 인덱스 등의 통계 정보를 활용하여 SQL문을 실행하는데 소요될 처리시간 및 CPU, I/O 지원량 등을 계산하여 가장 효율적인 것으로 예상되는 실행계획을 선택하는 옵티마이저를 말한다. 계산된 소용비용에 따라 인덱스가 존재하더라도 전체 테이블 스캔이 유리하다고 판단할 수도 있다.
실행계획
실행계획(Execution Plan)이란 SQL에서 요구한 사항을 처리하기 위한 절차와 방법을 의미한다. 실행계획이 달라지면 실행시간(성능)은 서로 다를 수 있지만 결과가 달라지지는 않는다.
실행계획 정보의 구성요소

- 최적화 정보 : 옵티마이저가 실행계획의 각 단계마다 예상되는 비용 사항을 표시한 것으로, 비용(Cost), 건수(Cardinality), 메모리 양(Bytes)에 대한 정보가 있다.
- 실행순서 : 실행계획을 읽는 순서는 위에서 아래로, 안에서 밖으로 읽는다.
SQL 처리 흐름도
SQL 처리 흐름도(Access Flow Diagram)란 SQL의 내부적인 처리 절차(실행계획)를 시각적으로 표현한 도표이다. SQL 처리 흐름도만 보고 실행시간을 알 수는 없다.
인덱스
인덱스는 조회만을 위한 오브젝트로, 기본적인 목적은 검색 성능의 최적화이다. 하지만 Insert, Update, Delete 등과 같은 DML 작업은 인덱스를 함께 변경해야 하기 때문에 오히려 성능이 느려질 수 있다.
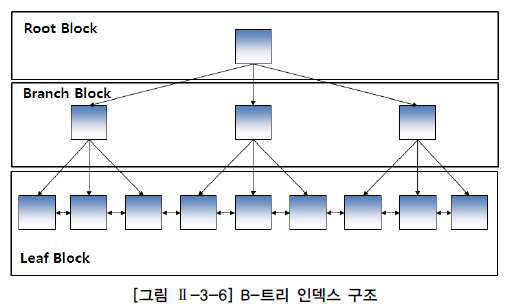
트리 기반 인덱스
DBMS에서 가장 일반적인 인덱스는 B-트리(Balance Tree) 인덱스이다. B-트리 인덱스는 브랜치 블록(Branch Block)과 리프 블록(Leaf Block)으로 구성되며, 브랜치 블록 중에서 가장 상위에서 있는 블록을 루트 블록(Root Block)이라고 한다. 브랜치 블록은 분기를 목적으로 하고 리프블록은 인덱스를 구성하는 컬럼의 값으로 정렬된다. 일반적으로 OLTP(Online transaction processing) 시스템 환경에서 가장 많이 사용된다.
CLUSTERED 인덱스
CLUSTERED 인덱스는 인덱스의 리프 페이지가 곧 데이터 페이지이며, 리프 페이지의 모든 데이터는 인덱스 키 칼럼 순으로 물리적으로 정렬되어 저장된다.
BITMAP 엔덱스
BITMAP 인덱스는 시스템에서 사용된 질의를 시스템 구현 시에 모두 알 수 없는 경우인 DW 및 AD-HOC 질의 환경을 위해서 설계되었으며, 하나의 인덱스 키 엔트리가 많은 행에 대한 포인터를 저장하고 있는 구조이다.
테이블 스캔
전체 테이블 스캔(FTS, FULL TABLE SCAN)
인덱스 스캔
- 인덱스 유일 스캔 : 유일 인덱스(Unique Index)를 사용하여 단 하나의 데이터를 추출하는 방식이다. 유일 인덱스는 중복을 허락하지 않는 인덱스이다. 유일한 인터넷 구성 칼럼에 모두 ‘=’로 값이 주어지면 결과는 최대 1건이 된다. 유일한 유인 인덱스 구성 컬럼에 대해 모두 ‘=’로 값이 주어진 경우에만 가능한 인덱스 스캔 방식이다.
- 인덱스 범위 스캔 : 인덱스를 이용하여 데이터를 추출하는 방식으로 , 결과 건수만큼 반환하지만 결과가 없으면 한 건도 반환하지 않을 수 있다.
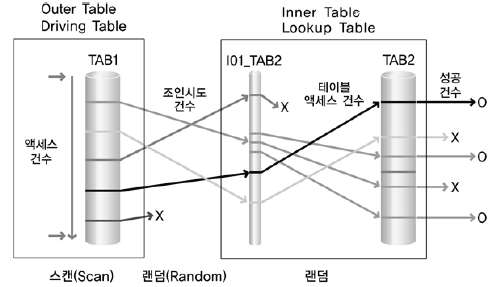
조인 기법
조인 기법에는 NL Join, Sort Merge Join, Hash Join 등이 있다. NL Login은 OLTP의 목록 처리 업무에 사용되고, Sort merge Join, Hahs Join응 DW(data warehouse) 등의 데이터 집계 업무에서 많이 사용된다.
NL Join(Nested Loop Join)
NL Join은 프로그램이에서 사용하는 중첩된 반복문과 유사한 방식으로 조인을 수행한다. 조인 칼럼에 적당한 인덱스가 있어야 자연조인(Natural Join)이 효율적일 때 유요하며, Driving Table(선행 테이블)의 조인 데이터 양이 큰 영향을 주는 조인 방식이다.
Sort Merge Join
Sort Merge Join은 조인 칼럼을 기준으로 데이터를 정렬하여 조인을 수행한다. NL Join은 주로 랜덤 액세스 방식으로 데이터를 읽는 방법 Sort Merge Join은 주로 스캔방식으로 데이터를 읽는다. Sort Merge Join은 랜덤 액세스로 NL Join에서 부담이 되던 넓은 범위의 데이터를 처리할 때 이용되던 조인 기법이다. 그러나 Sort Merge Join은 정렬할 데이터가 많아 메모리에서 모든 정렬 작업을 수행하기 어려운 경우에는 임시 영역(디스크)을 사용하기 때문에 성능이 떨어질 수 있다.
Hash Join
Hash Join은 해슁 기법을 이용하여 조인을 수행한다. Hash Join은 조인 칼럼의 인덱스를 사용하지 않기 때문에 조인 칼럼의 인덱스가 존재하는 경우에도 사용할 수 있는 조인 기법이다. Hash Join은 해쉬 함수를 이용하여 조인을 수행하기 때문에 ‘=’로 수행하는 조인 즉, 동등 조인(EQUI JOIN)에서만 사용할 수 있다.
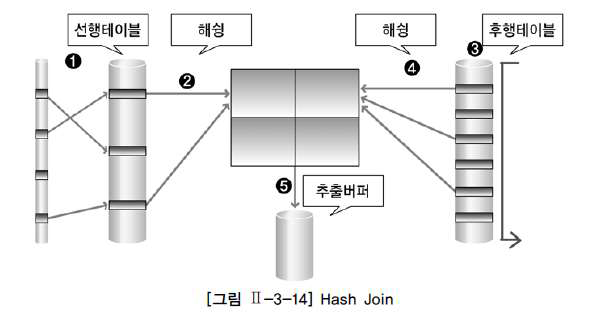
그림과 같이 Hash Join은 조인 작업을 수행하기 위해 해쉬 테이블을 메모리에 생성해야 한다. 생성된 해쉬 테이블의 크기가 메모리에 적재할 수 있는 크기보다 더 커지면서 임시 영어(디스크)에 해쉬 테이블을 저장한다. 그러면 추가적인 작업이 필요해진다. 그렇기 때문에 Hash Join을 할 때는 결과 행의 수가 적은 테이블을 선행 테이블로 사용하는 것이 좋다.